I recently created a Python script to backup my Goodreads shelves.
I have now created a little web app to let anyone backup their Goodreads shelves using a quite simple web interface.
I wrote a bit about my Goodreads Python Script project a while back: New Mini Project - Goodreads Backup
Now I have created a little web app with a tiny frontend and backend.
Frontend is written in HTML, CSS and JavaScript (with jQuery). Backend is written in Java and Spring Boot.
If you want to give it a spin, a working deployment can be found here: http://demo.gjermundbjaanes.com:8080/goodreads-backup/
How it works
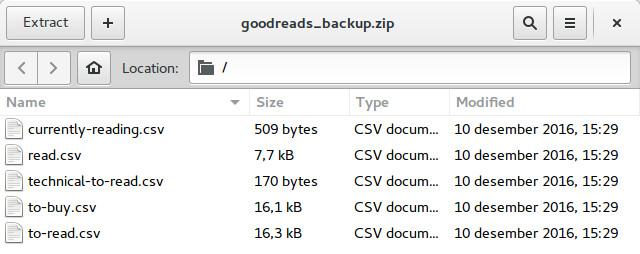
The app works by taking in the users Goodreads User ID and creating a backup file that the user can download. The backup file contains the users shelves saved as CSV files.
Entering your Goodreads ID
You just enter your ID in the text field and click the button next to it:
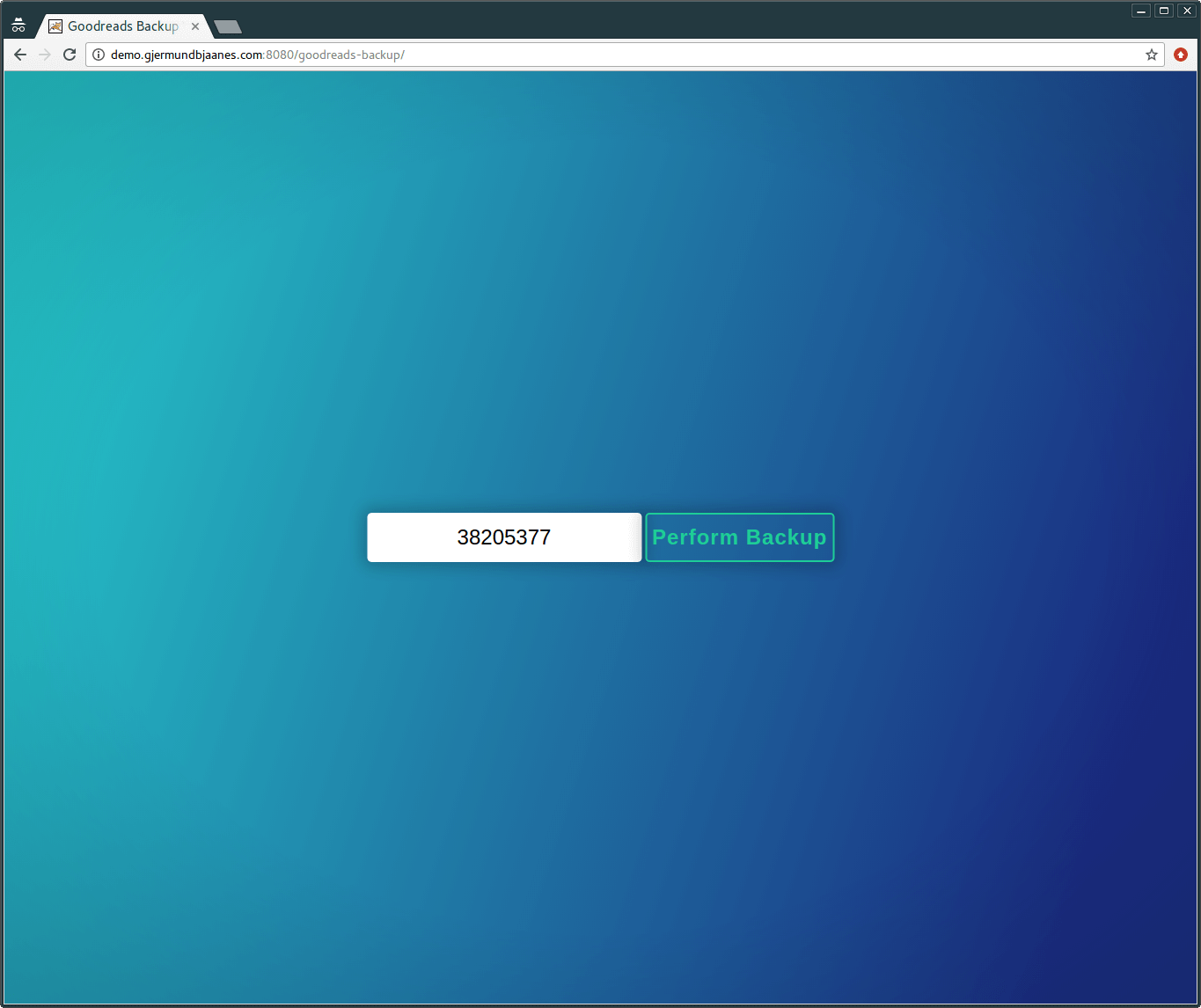
(You can find your own id by logging into Goodreads and opening up your profile. In the url, you see your ID):

I have created a few tickets on GitHub to make this a bit easier for the user, but for now, it works at least. If you feel inclined to help out, please do!
The backup process can take some time, depending on the amount of books you have in your shelves:
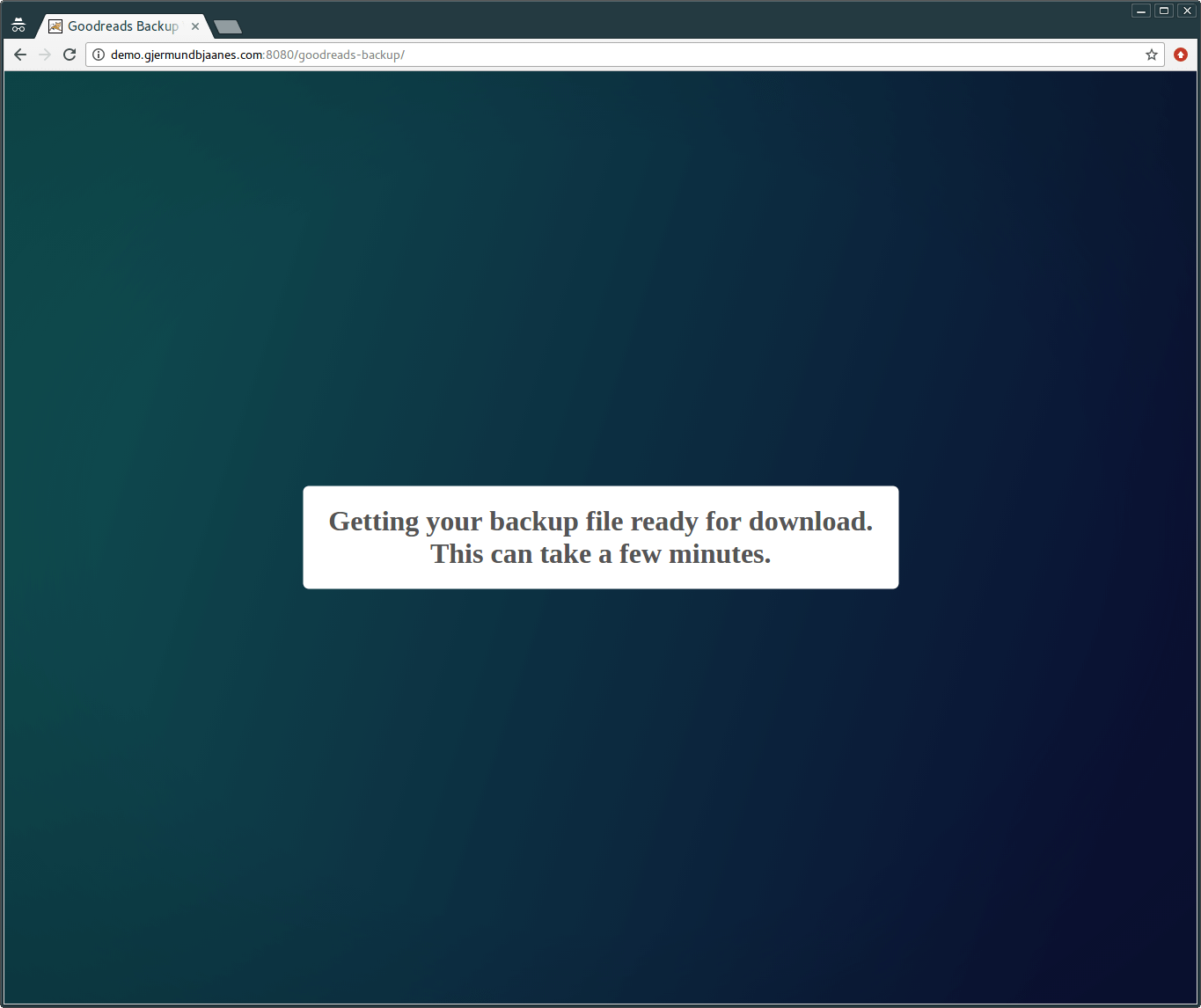
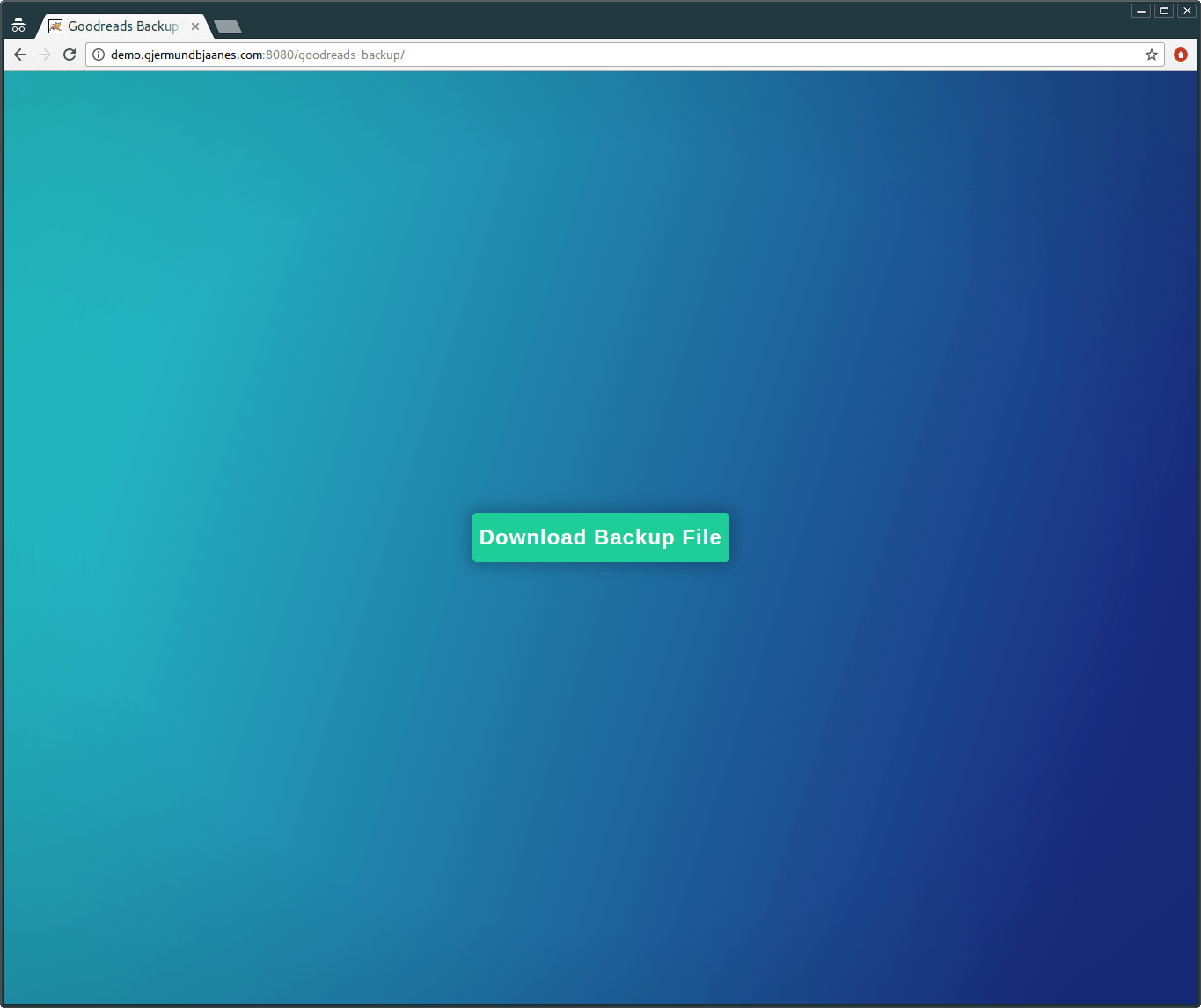
Downloading the file
Once the file is ready, you can download the file from the server.
All shelves are finally in your possession!
How it works - A bit more technical
Now that I have shown you how to work the app, I thought it might be interesting to walk through the more technical aspects of the flow.
The process works like so:
- Users enters ID and clicks the “Perform Backup” button
- Server receives a REST call with the Goodreads User ID
- Server creates a temp directory to keep output from the Python Script
- Server executes the Python Script with the Goodreads User ID
- When the script is finished (running the backup), a zip file is created with all the CSV files.
- Server returns a backup ID to the client
- Client is notified that the process is done, prompting the user to download their backup file
- User Clicks the “Download Backup File” button
- Server receives a different REST call with the backup ID
- Server creates a lock file for the backup (so it won’t get deleted while the client downloads it).
- Server streams zip file back to the user
- Server deletes the backup file from the file system
- User gets their backup file
The server also has a separate step that it is running periodically to clean up the file system. If a file has not been downloaded and deleted within a certain time limit, the file will be deleted automatically (and the user will have to perform their backup again).
Open Source - of course
If you want to take a look at the code, it is as always available on GitHub: https://github.com/bjaanes/goodreads-backup-web
Feel free to do any improvement you see fit. Or just reach out if you want to chat about the code. I love talking about code!
 Follow me on Twitter: @gjermundbjaanes
Follow me on Twitter: @gjermundbjaanes